About Us
The argument in favor of using filler text goes something like this: If you use real content in the Consulting Process, anytime you reach a review point you’ll end up reviewing and negotiating the content itself and not the design.
ConsultationContact Info
- Tầng 20, Tòa nhà Software Park 02 Quang Trung, Phường Thạch Thang Quận Hải Châu, TP Đà Nẵng
- (+84 236) 6299 289
- contact_vbpo@vbpo.com.vn
Blog 4.0
Ký sự 4.0
Các khái niệm cơ bản về Dán nhãn dữ liệu trong Machine Learning
Tham khảo thêm về dịch vụ Data Annotation đang được VBPO JSC cung cấp tại đường dẫn:
https://vbpo.com.vn/our-services/data-processing-solutions/data-annotation
Bạn có rất nhiều dữ liệu chưa được dán nhãn? Hầu hết dữ liệu không ở dạng được dán nhãn và đây là một thách thức lớn với dự án AI. Theo phân tích của Cognilytica, một dự án AI dành 80% thời gian cho việc thu thập, sắp xếp và dán nhãn dữ liệu. Trong cuộc chạy đua công nghệ khắc nghiệt hiện nay thì quỹ thời gian đó là vô cùng quý giá. Một bộ dữ liệu hoàn chỉnh được cấu trúc và dán nhãn đúng là bước chạy đà quan trọng nhất phục vụ cho mục đích đào tạo và triển khai các mô hình.
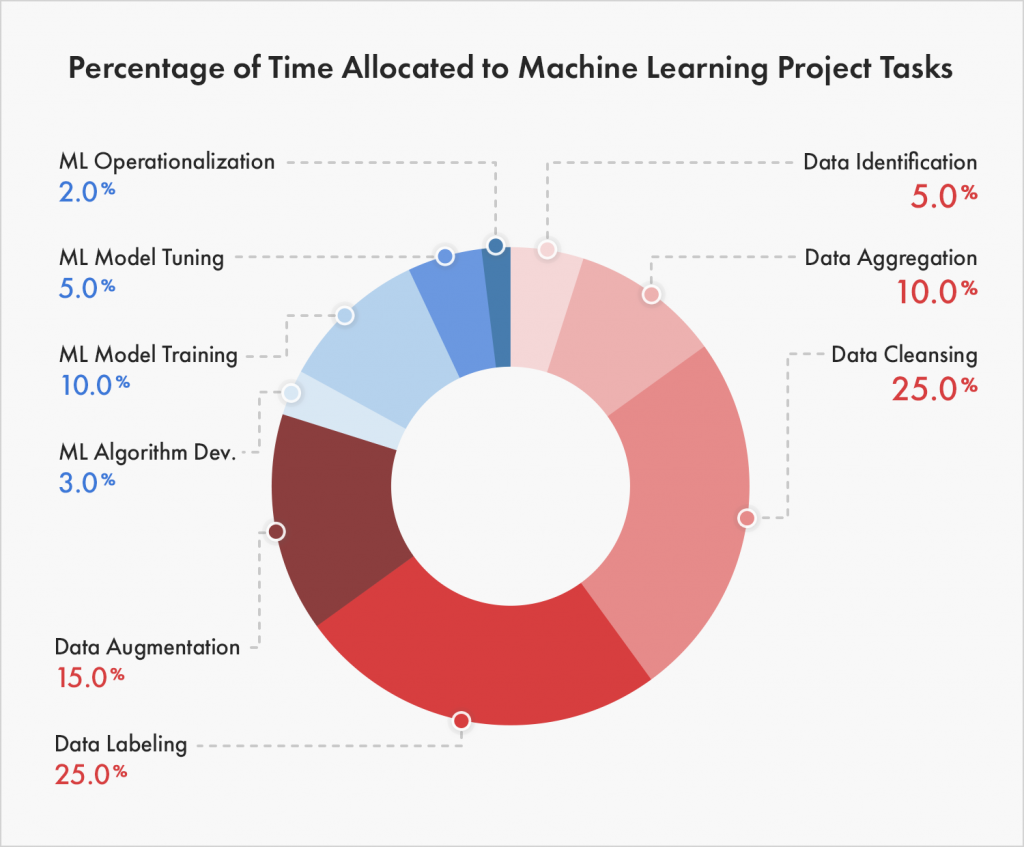
Dữ liệu có chất lượng dán nhãn thấp: Có rất nhiều lý do dẫn đến vấn đề này, nhưng thông thường nguyên nhân gốc xuất phát từ con người, quy trình hoặc công nghệ được sử dụng trong quy trình ghi nhãn dữ liệu.
Tốc độ dán nhãn dữ liệu chậm: Mô hình hiện tại còn nhỏ, cần tăng thêm lượng dữ liệu cần dán nhãn nhanh. Nếu chỉ sử dụng nhân sự nội bộ, sẽ rất khó khăn và tốn kém để mở rộng quy mô.
Quá trình ghi nhãn dữ liệu hiện tại là không hiệu quả hoặc tốn kém: Nếu doanh nghiệp đang sử dụng data scientists cho việc chuẩn hóa dữ liệu thì tìm một cách tiếp cận khác là giải pháp tối ưu hơn. Mức lương cho data scientists chắc chắn cao hơn nhiêu khi sử dụng nhân sự có chuyên môn dành riêng cho gán dữ liệu. Sẽ là sự lãng phí quĩ lương khi chi vào công việc cơ bản, lặp đi lặp lại.
Quy trình dán dữ liệu hiện tại chưa được đảm bảo chất lượng, hoặc bộ phận QA cần cải tiến: Đây là một lĩnh vực thường bị bỏ qua của việc ghi nhãn dữ liệu có thể cung cấp giá trị quan trọng, đặc biệt là trong các giai đoạn kiểm tra và xác thực mô hình học máy lặp.
Read more about Data Annotation: https://data-annotation.vbpo.com.vn/
Dán nhãn dữ liệu có phức tạp?
Dữ liệu được dán nhãn là gì?
Trong machine learning, nếu dữ liệu đã được gán nhãn, điều đó có nghĩa dữ liệu được đánh dấu hoặc chú thích, để hiển thị mục tiêu, đây cũng là câu trả lời bạn muốn mô hình học máy của mình dự đoán. Nói chung, ghi nhãn dữ liệu có thể đề cập đến các tác vụ bao gồm gắn thẻ dữ liệu, chú thích, phân loại, kiểm duyệt, sao chép hoặc xử lý.
Chú thích dữ liệu là gì?
Chú thích dữ liệu thường đề cập đến quá trình ghi nhãn dữ liệu. Chú thích dữ liệu và ghi nhãn dữ liệu thường được sử dụng thay thế cho nhau, mặc dù chúng có thể được sử dụng khác nhau dựa trên các ngành đặc thù hoặc trường hợp sử dụng.
Dữ liệu được gắn nhãn làm nổi bật các tính năng dữ liệu – hoặc các thuộc tính, đặc điểm hoặc phân loại – có thể được phân tích cho các mẫu giúp dự đoán mục tiêu. Ví dụ, trong thị giác máy tính cho xe tự hành, một người ghi nhãn dữ liệu có thể sử dụng các công cụ ghi nhãn video theo từng khung để chỉ ra vị trí của biển báo đường phố, người đi bộ hoặc các phương tiện khác.
“Con người trong vòng lặp” (human in the loop – HITL) là gì?
HITL tận dụng cả trí tuệ của con người và máy móc để tạo ra các mô hình học máy. Trong cấu hình vòng lặp của con người, mọi người tham gia vào một vòng cải tiến có đạo đức trong đó phán đoán của con người được sử dụng để đào tạo, điều chỉnh và kiểm tra một mô hình dữ liệu cụ thể.
Các nhãn trong học máy là gì?
Nhãn là thứ mà vòng lặp con người (HITL) sử dụng để xác định và gọi ra các tính năng có trong dữ liệu. Việc này rất quan trọng để chọn các tính năng thông tin, phân biệt đối xử và độc lập để gắn nhãn nếu bạn muốn phát triển các thuật toán hiệu suất cao trong nhận dạng, phân loại và hồi quy. Dữ liệu được dán nhãn chính xác có thể cung nền tảng vững chắc để thử nghiệm và lặp lại các mô hình.
Sự thật nền tảng ( ground truth ) trong học máy là gì?
Trong học máy, sự thật nền tảng có nghĩa kiểm tra kết quả của các thuật toán machine learning để biết độ chính xác so với thế giới thực. Về bản chất, đây là một kiểm tra thực tế cho tính chính xác của các thuật toán. Thuật ngữ này được mượn từ khí tượng học, trong đó “Sự thật nền tảng” dùng để chỉ thông tin thu được trên mặt đất nơi xảy ra sự kiện thời tiết, dữ liệu đó được so sánh với các mô hình dự báo để xác định độ chính xác của chúng.
Dữ liệu đào tạo (training data) trong học máy là gì?
Dữ liệu đào tạo là dữ liệu phong phú mà bạn sử dụng để đào tạo thuật toán hoặc mô hình học máy.
Các công ty hiện nay dán nhãn dữ liệu bằng cách nào?
Các tổ chức sử dụng kết hợp phần mềm, quy trình và con người để làm sạch, cấu trúc hoặc gắn nhãn dữ liệu. Có bốn tùy chọn chính cho lực lượng ghi nhãn dữ liệu:
- Nhân viên: Họ thuộc biên chế công ty, toàn thời gian hoặc bán thời gian. Mô tả công việc của họ có thể không bao gồm ghi nhãn dữ liệu.
- Các nhóm được quản lý: Nhân lực thuê ngoài được chính bạn quản lý, có kinh nghiệm và đào tạo bài bản cho nghiệp vụ dãn nhãn dữ liệu (Ví dụ: VBPO)
- Nhà thầu: Nhân viên tạm thời hoặc là freelancer.
- Crowdsourcing: Bạn sử dụng nền tảng của bên thứ ba để truy cập số lượng lớn nhân lực cùng một lúc.
*Nguồn: testerviet.com.vn