About Us
The argument in favor of using filler text goes something like this: If you use real content in the Consulting Process, anytime you reach a review point you’ll end up reviewing and negotiating the content itself and not the design.
ConsultationContact Info
- Tầng 20, Tòa nhà Software Park 02 Quang Trung, Phường Thạch Thang Quận Hải Châu, TP Đà Nẵng
- (+84 236) 6299 289
- contact_vbpo@vbpo.com.vn
Blog 4.0
Ký sự 4.0
Data Annotation - Ghi nhãn dữ liệu là gì?
Một trong những bước tốn thời gian nhất trong vòng đời của thuật toán trí tuệ nhân tạo là thu thập dữ liệu và chuẩn bị nó. Mô hình học sâu sẽ chỉ hoạt động tốt như dữ liệu đào tạo của bạn. Và do đó, ý tôi là dữ liệu phù hợp với nhiệm vụ của chúng tôi và được chú thích. Chú thích dữ liệu, cũng thường được gọi là gán nhãn dữ liệu, chắc chắn là bước khó nhất và lâu nhất sẽ khiến ứng dụng của bạn thất bại hoặc thành công.
> Xem thêm dịch vụ Data Annotation mà VBPO đang cung cấp
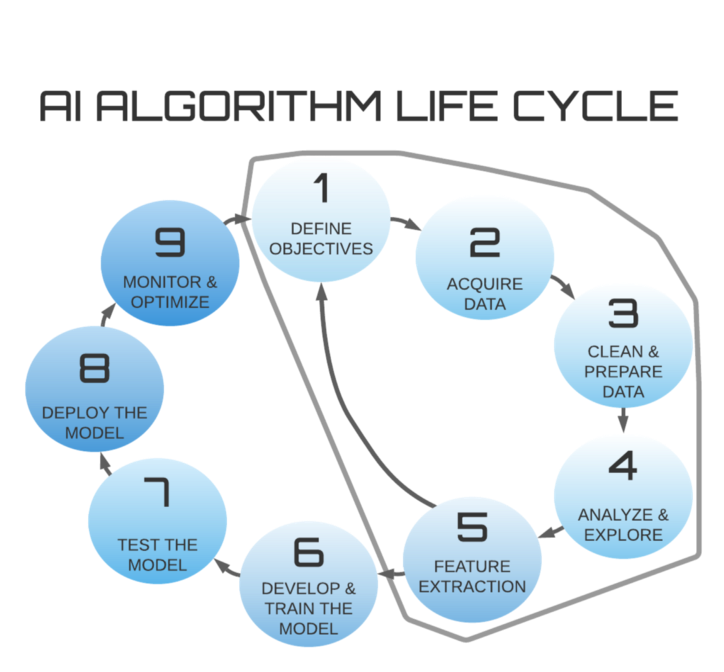
Gán nhãn dữ liệu là gì?
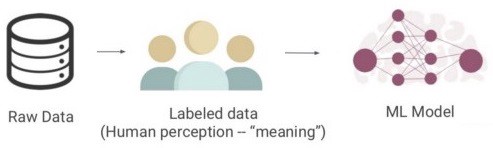
Gán nhãn dữ liệu là quá trình gắn ý nghĩa với dữ liệu số. Quá trình này có thể thủ công nhưng thường được thực hiện hoặc được hỗ trợ bởi phần mềm và cần có sự tiếp xúc của con người. Gán nhãn dữ liệu là phần quan trọng nhất của quá trình tiền xử lý dữ liệu cho các thuật toán học máy, đặc biệt đối với học có giám sát, trong đó cả dữ liệu đầu vào và đầu ra đều được gắn nhãn để phân loại nhằm cung cấp cơ sở học tập cho việc xử lý dữ liệu trong tương lai. Các nhãn này có thể có nhiều dạng, chẳng hạn như chú thích hình ảnh, chú thích văn bản, chú thích video và thậm chí cả chú thích âm thanh. Nói tóm lại, về cơ bản, mọi thông tin bổ sung về dữ liệu được cung cấp cho thuật toán của chúng tôi sẽ điều chỉnh nó để đạt được kết quả chính xác và mong muốn.
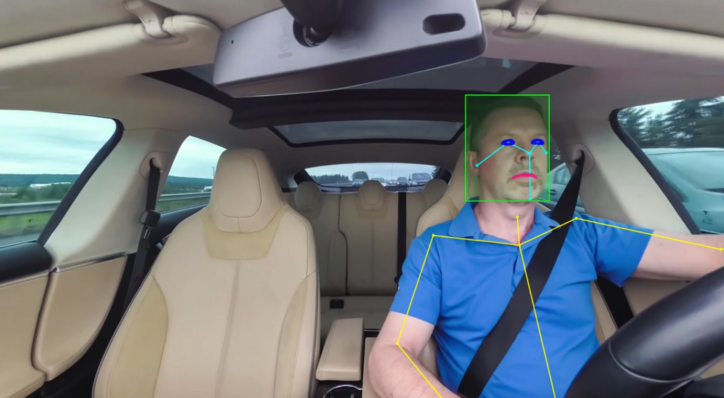
Ví dụ: nếu chúng tôi sử dụng hệ thống an toàn đường bộ và đào tạo hệ thống này để xác định xem ai đó đang nhìn đường hay không khi đang lái xe. Chúng tôi có thể được cung cấp nhiều video về các tài xế và ô tô khác nhau được chú thích, trông giống như video này, trong đó nó sẽ có thêm thông tin về vị trí khuôn mặt của một người và cụ thể hơn là mắt của anh ta. Từ các ví dụ video này, thuật toán sẽ tìm hiểu các đặc điểm chung của mỗi ví dụ, trong trường hợp này sẽ là hiểu người đó đang nhìn ở đâu, cho phép xác định chính xác xem người đó có đang nhìn đường trong hình ảnh không nhìn thấy và không được dán nhãn hay không.
> Read more: VBPO Data Annotation

Chúng ta biết rằng các hệ thống học sâu thường yêu cầu một lượng lớn dữ liệu để thiết lập nền tảng cho các mô hình học tập đáng tin cậy. Chúng tôi cần hàng nghìn hình ảnh huấn luyện, ngay cả đối với một ứng dụng đơn giản, như một mô hình có thể phân biệt một con chó với một con mèo. Dữ liệu họ sử dụng để cung cấp thông tin cho việc học phải được gắn nhãn hoặc chú thích, có nghĩa là mọi thứ hoặc chỉ những thứ quan trọng nhất phải được xác định hoặc bản địa hóa trong hình ảnh. Đây thường được gọi là "sự thật cơ bản" cho thuật toán học sâu của chúng tôi. Đó là những gì chúng tôi muốn nó có thể tìm thấy về các hình ảnh được cung cấp. Hơn nữa, nó phải được gắn nhãn dựa trên các tính năng dữ liệu giúp mô hình tổ chức dữ liệu thành các mẫu tạo ra câu trả lời mong muốn. Chẳng hạn như tên của lớp trong ví dụ cơ bản này, là "mèo" hoặc "chó". Tập dữ liệu được gắn nhãn thích hợp cung cấp sự thật cơ bản mà mô hình học máy sử dụng để kiểm tra độ chính xác của các dự đoán và tiếp tục tinh chỉnh thuật toán của nó. Điều này rất quan trọng để làm cho mô hình tổng thể của chúng tôi tốt hơn.
Các lỗi trong gán nhãn dữ liệu làm giảm chất lượng của tập dữ liệu đào tạo và hiệu suất của bất kỳ mô hình dự đoán nào mà nó được sử dụng. Để giảm thiểu điều này, nhiều công ty, chẳng hạn như Keymakr, áp dụng phương pháp tiếp cận con người trong vòng lặp (HITL). Vai trò này thường được gọi là “Người gán nhãn dữ liệu”, duy trì sự tham gia của con người vào việc đào tạo và thử nghiệm các mô hình dữ liệu trong suốt quá trình phát triển lặp đi lặp lại của họ. Cách tiếp cận nhân bản này là điều cần thiết để tạo ra một tập dữ liệu tốt và đảm bảo không có lỗi nào có thể ảnh hưởng đến thuật toán của chúng tôi.
Chỉ cần nhìn vào các chi tiết nhỏ và sự chú ý cần thiết để tạo ra một tập dữ liệu tuyệt vời như vậy từ ảnh vệ tinh và dữ liệu GPS, chú thích từng phần tử với độ chính xác cao nhất có thể. Một thuật toán tốt với tập dữ liệu được chú thích kém sẽ hoạt động kém với tỷ lệ nhận dạng thấp. Do đó, chúng tôi cần một tập dữ liệu được gắn nhãn tốt, với số lượng hiện vật ít nhất có thể, điều này có thể cực kỳ khó tạo khi bạn không phải là chuyên gia về dữ liệu gắn nhãn.
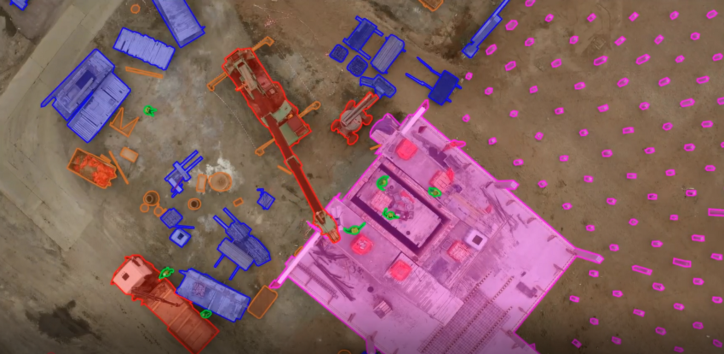
Gán nhãn dữ liệu thủ công là phương pháp tốn thời gian và tốn kém nhất, nhưng nó cần thiết cho nhiều ứng dụng quan trọng, chẳng hạn như xe tự hành, nhận dạng khối u não, nhận dạng khuôn mặt, v.v. May mắn thay cho chúng tôi, một số công ty chuyên về dịch vụ này, như VBPO. Một công ty như vậy có thể cung cấp cho bạn các chú thích dữ liệu mà bạn đang tìm kiếm để tạo ra thuật toán lý tưởng của bạn. Chỉ cần xem có bao nhiêu chi tiết được yêu cầu trong các chú thích ở đây do nhóm của Keymakr thực hiện. Việc tự mình tạo ra một tập dữ liệu hoàn chỉnh và được chú thích chính xác như vậy sẽ mất hàng trăm giờ làm việc mà bạn có thể đưa vào nghiên cứu và thử nghiệm ứng dụng của mình.

Các loại gán nhãn dữ liệu khác nhau
Kiểu gán nhãn dữ liệu đơn giản và phổ biến nhất là phân loại, trong đó chúng tôi phân loại hình ảnh theo đối tượng mà nó chứa. Sau đó, có nhiều chú thích phức tạp và đầy đủ hơn cho các vấn đề khó hơn, chẳng hạn như phân đoạn ngữ nghĩa, hộp giới hạn, chú thích khung (lưới), v.v.



Bây giờ, tôi muốn dành một phút để nói thêm về các loại chú thích này và nhà tài trợ của bài viết này: VBPO. Sứ mệnh của VBPO là đóng góp vào việc định hình và xây dựng những công nghệ tiên tiến và cao cấp nhất của tương lai. Như tôi đã nói trước đó trong bài viết, họ cũng tin rằng bất kỳ thuật toán trí tuệ nhân tạo nào cũng chỉ có thể hoạt động tốt như dữ liệu đào tạo được sử dụng để tạo ra nó và điều đó luôn bắt đầu với sự tiếp xúc của con người. Thực hiện đúng cách, nó có khả năng vô tận!
Họ cung cấp nhiều dịch vụ chú thích trong nhiều ngành, chẳng hạn như:
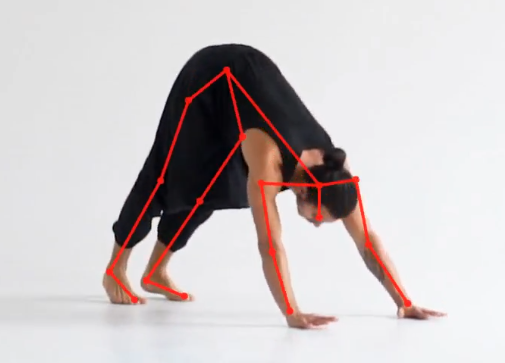
Các chú thích chính xác về bộ xương, được hiển thị ở đây trong ví dụ ứng dụng trong cabin này. Nó có thể theo dõi các chuyển động phức tạp như ai đó đang tập yoga. Hoặc thậm chí theo dõi nhiều người cùng một lúc. Về cơ bản, nó hiển thị bộ xương của người để giúp theo dõi cảm xúc, đối tượng, hành vi, v.v.
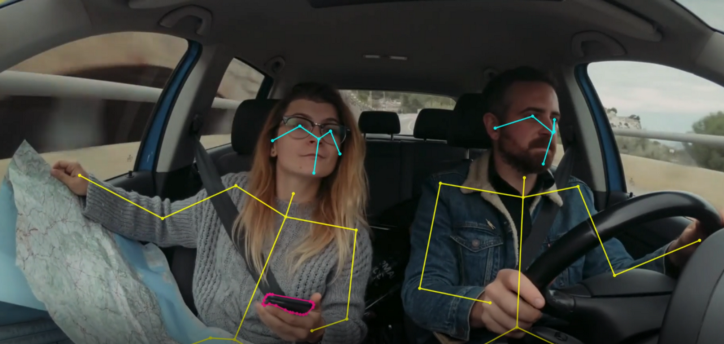

Chú thích chính xác về hộp Boundary, ở đây trong ví dụ ứng dụng chuẩn bị dữ liệu đào tạo về thị giác máy tính trên không, có thể được sử dụng để báo cáo giao thông đường bộ. Hộp giới hạn cũng có thể được sử dụng trong nhiều ứng dụng thị giác máy tính khác, nơi chúng ta cần theo dõi một người hoặc đối tượng cụ thể, chẳng hạn như những người trong một ứng dụng bảo mật được hiển thị ở đây.

Như bạn có thể thấy, VBPO cung cấp rất nhiều loại dịch vụ chú thích khác nhau trong vô số ngành và tôi chắc chắn khuyên bạn nên sử dụng dịch vụ của họ nếu bạn cần một bộ dữ liệu tuyệt vời cho bất kỳ ứng dụng trí tuệ nhân tạo nào, bạn có thể truy cập trang web https://vbpo.com.vn/ của chúng tôi để tham khảo thêm các dịch vụ khác.
Nhóm của VBPO thực hiện một cách tiếp cận tùy chỉnh và độc đáo cho trường hợp của bạn bằng cách sử dụng các công cụ chú thích nâng cao với hiệu quả tối đa. Thực hiện một trong những quy trình tốn nhiều thời gian nhất, khá nhanh và tiết kiệm chi phí.
*Nguồn: Keymakr.com