About Us
The argument in favor of using filler text goes something like this: If you use real content in the Consulting Process, anytime you reach a review point you’ll end up reviewing and negotiating the content itself and not the design.
ConsultationContact Info
- Tầng 20, Tòa nhà Software Park 02 Quang Trung, Phường Thạch Thang Quận Hải Châu, TP Đà Nẵng
- (+84 236) 6299 289
- contact_vbpo@vbpo.com.vn
Blog 4.0
Ký sự 4.0
Dữ liệu tổng hợp giải quyết thách thức về dữ liệu của AI
AI đang phải đối mặt với một số thách thức quan trọng. Nó không chỉ cần một lượng lớn dữ liệu để cho ra kết quả chính xác mà còn cần có khả năng đảm bảo rằng dữ liệu đó không chứa thành kiến, đồng thời tuân thủ các quy định ngày càng nghiêm ngặt về quyền riêng tư dữ liệu. Chúng ta đã thấy một số giải pháp được đưa ra trong vài năm qua để giải quyết những thách thức này – bao gồm các công cụ khác nhau được thiết kế để xác định và giảm thiểu thành kiến, các công cụ ẩn danh dữ liệu người dùng và các chương trình đảm bảo dữ liệu chỉ được thu thập khi có sự đồng ý của người dùng. Nhưng mỗi giải pháp lại đang đối mặt với những thách thức riêng.
Hiện nay, chúng ta đang chứng kiến một ngành mới xuất hiện, hứa hẹn sẽ trở thành một điểm sáng: dữ liệu tổng hợp. Dữ liệu tổng hợp là dữ liệu nhân tạo do máy tính tạo ra để thay thế cho dữ liệu thu thập từ thế giới thực.
Một tập dữ liệu tổng hợp phải có cùng các thuộc tính toán học và thống kê với tập dữ liệu của thế giới thực mà nó đang thay thế, nhưng không đại diện rõ ràng cho các cá nhân thực. Hãy coi đây là một tấm gương kỹ thuật số của dữ liệu thế giới thực, phản ánh về mặt thống kê của thế giới đó. Điều này cho phép đào tạo các hệ thống AI trong một vùng đất ảo. Đồng thời, nó có thể được tùy chỉnh dễ dàng cho nhiều trường hợp sử dụng khác nhau, từ y tế đến bán lẻ, tài chính, giao thông vận tải và nông nghiệp.
Có một sự vận động đáng kể đang diễn ra trên mặt trận này. Hơn 50 nhà cung cấp đã phát triển các giải pháp dữ liệu tổng hợp, theo như nghiên cứu vào tháng 6 năm ngoái của StartUs Insights. Lát nữa, tôi sẽ phác thảo về một số công ty đang đi đầu. Tuy nhiên, trước tiên, chúng ta hãy xem xét kỹ hơn các vấn đề mà họ hứa hẹn sẽ giải quyết.
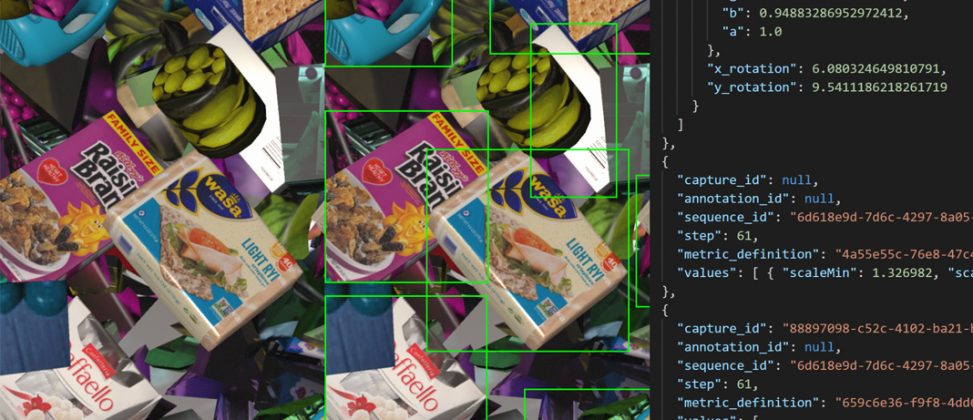
Trở ngại của dữ liệu thực
Trong vài năm qua, ngày càng có nhiều lo ngại về việc các thành kiến cố hữu trong các tập dữ liệu có thể vô tình khiến các thuật toán AI tiếp tục sự phân biệt đối xử có hệ thống. Trên thực tế, Gartner dự đoán rằng đến năm 2022, 85% các dự án AI sẽ mang lại kết quả sai lệch do thành kiến trong dữ liệu, thuật toán, hay trong đội ngũ phụ trách việc quản lý chúng.
Sự phát triển của các thuật toán AI cũng dẫn đến mối lo ngại ngày càng tăng về quyền riêng tư dữ liệu. Đổi lại, điều này đã dẫn đến các luật bảo vệ quyền riêng tư của dữ liệu người dùng mạnh mẽ hơn ở EU với GDPR, cũng như các khu vực pháp lý của Hoa Kỳ, bao gồm California và gần đây nhất là Virginia.
Những luật này cho phép người tiêu dùng có nhiều quyền kiểm soát dữ liệu cá nhân hơn. Ví dụ: Luật Virginia cấp cho người tiêu dùng quyền truy cập, chỉnh sửa, xóa và lấy bản sao dữ liệu cá nhân, cũng như từ chối bán dữ liệu cá nhân và từ chối việc truy cập sử dụng thuật toán vào dữ liệu cá nhân nhằm mục đích quảng cáo nhắm mục tiêu hay phân tích người tiêu dùng.
Bằng cách hạn chế quyền truy cập vào các thông tin này, một số biện pháp bảo vệ cá nhân sẽ thành công, nhưng chúng ta phải trả giá bằng hiệu quả của thuật toán. Thuật toán AI được đào tạo với càng nhiều dữ liệu thì kết quả càng chính xác và hiệu quả. Nếu không có quyền truy cập vào dữ liệu phong phú, những mặt tích cực của AI, chẳng hạn như trợ giúp chẩn đoán y tế và nghiên cứu thuốc, cũng có thể bị hạn chế.
Một giải pháp thay thế thường được sử dụng để bù đắp những lo ngại về quyền riêng tư là ẩn danh. Ví dụ, dữ liệu cá nhân có thể được ẩn danh bằng cách che dấu hoặc loại bỏ các đặc điểm nhận dạng như xoá tên và số thẻ tín dụng khỏi các giao dịch thương mại điện tử, hay xóa nội dung nhận dạng khỏi hồ sơ chăm sóc sức khỏe. Tuy nhiên, ngày càng có nhiều bằng chứng cho thấy ngay cả khi dữ liệu đã được ẩn danh từ một nguồn, nó có thể tương quan với tập dữ liệu người tiêu dùng khác đã bị lộ do vi phạm bảo mật. Trên thực tế, bằng cách kết hợp dữ liệu từ nhiều nguồn, việc tạo ra một bức tranh rõ ràng một cách đáng ngạc nhiên về danh tính của chúng ta là điều có thể xảy ra, ngay cả khi đã được ẩn danh ở một mức độ nào đó. Trong một số trường hợp, điều này thậm chí có thể được thực hiện bằng cách so sánh dữ liệu từ các nguồn công khai mà không có hành vi hack bảo mật bất chính.
Giải pháp của dữ liệu tổng hợp
Dữ liệu tổng hợp hứa hẹn mang lại những lợi thế của AI mà không có các mặt tiêu cực. Không chỉ đưa dữ liệu cá nhân thực của chúng ta ra khỏi phương trình, dữ liệu tổng hợp còn có mục tiêu chung là hoạt động tốt hơn dữ liệu thế giới thực bằng cách sửa chữa các thành kiến được khắc sâu trong thế giới thực.
Mặc dù lý tưởng cho các ứng dụng sử dụng dữ liệu cá nhân, thông tin tổng hợp cũng có các công dụng khác, ví dụ như mô hình thị giác máy tính phức tạp có nhiều yếu tố tương tác trong thời gian thực. Tận dụng các công cụ game tiên tiến, các tập dữ liệu video tổng hợp có thể được tạo ra với hình ảnh siêu thực tế để miêu tả tất cả các tình huống có thể xảy ra trong trong một kịch bản lái xe tự động. Trong khi đó, việc cố gắng chụp ảnh hoặc quay phim thế giới thực để ghi lại tất cả các sự kiện sẽ không thực tế, có lẽ là không thể, và có vẻ nguy hiểm. Những tập dữ liệu tổng hợp này có thể tăng tốc đáng kể và cải thiện việc đào tạo các hệ thống lái xe tự hành.
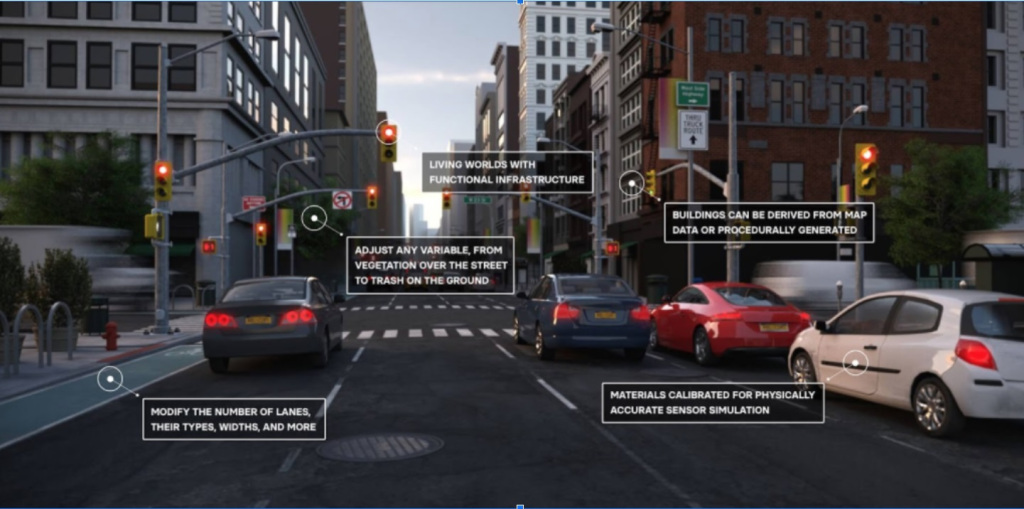
Có lẽ thật trớ trêu khi một trong những công cụ chính để xây dựng dữ liệu tổng hợp lại chính là công cụ được sử dụng để tạo video deepfake. Cả hai đều sử dụng mạng đối nghịch tạo sinh (GAN), một cặp mạng thần kinh. Một mạng tạo ra dữ liệu tổng hợp và mạng thứ hai cố gắng phát hiện xem nó có thật hay không. Điều này được vận hành theo một vòng lặp, với mạng tạo sinh cải thiện chất lượng dữ liệu cho đến khi mạng phân biệt không thể chỉ ra sự khác nhau giữa dữ liệu thực và dữ liệu tổng hợp.
Hệ sinh thái mới xuất hiện
Gần đây, Forrester Research đã xác định một số công nghệ quan trọng, bao gồm dữ liệu tổng hợp, sẽ trở thành một phần của thứ mà họ gọi là “AI 2.0” – những tiến bộ giúp mở rộng hoàn toàn các khả năng của AI. Bằng cách ẩn danh dữ liệu trọn vẹn hơn và sửa lại những thành kiến cố hữu, cũng như tạo ra các dữ liệu vốn khó thu được, dữ liệu tổng hợp có thể trở thành vị cứu tinh cho nhiều ứng dụng dữ liệu lớn.
Dữ liệu tổng hợp cũng đi kèm với một số lợi ích lớn khác: Bạn có thể tạo ra các tập dữ liệu nhanh chóng và thường xuyên với dữ liệu được gắn nhãn cho việc học có giám sát. Nó cũng không cần phải được làm sạch và bảo trì như dữ liệu thực. Vì vậy, ít nhất về mặt lý thuyết, nó đi kèm với một khoản tiết kiệm lớn về thời gian và chi phí.
Một số công ty lâu đời đang nằm trong số những công ty tạo ra dữ liệu tổng hợp. IBM mô tả điều này là sự ngụy tạo dữ liệu, tạo ra dữ liệu thử nghiệm tổng hợp để loại bỏ nguy cơ rò rỉ thông tin bí mật, giải quyết GDPR và các vấn đề về quy định. AWS đã phát triển các công cụ tổng hợp dữ liệu nội bộ để tạo bộ dữ liệu nhằm đào tạo Alexa về các ngôn ngữ mới. Microsoft cũng đã hợp tác cùng Harvard phát triển một công cụ với khả năng tạo ra dữ liệu tổng hợp cân nhắc sự tăng cường hợp tác giữa các bên nghiên cứu. Bất chấp những ví dụ này, đây vẫn là những ngày đầu của dữ liệu tổng hợp và các startup đang dẫn đầu thị trường đang phát triển này.
Để tóm tắt lại, hãy cùng điểm qua một số nhà lãnh đạo đầu tiên của lĩnh vực mới xuất hiện này. Danh sách này được xây dựng dựa trên nghiên cứu của riêng tôi và các tổ chức nghiên cứu ngành, bao gồm G2 và StartUs Insights.
- AiFi – Sử dụng dữ liệu tổng hợp để mô phỏng các cửa hàng bán lẻ và hành vi người mua sắm.
- AU.Reverie – Tạo ra dữ liệu tổng hợp để đào tạo các thuật toán thị giác máy tính cho nhận diện hoạt động, phát hiện vật thể và phân đoạn. Công trình bao gồm nhiều quang cảnh như thành phố thông minh, nhận dạng máy bay hiếm và nông nghiệp, cùng với cửa hàng bán lẻ thông minh.
- Anyverse – Mô phỏng các kịch bản để tạo ra các tập dữ liệu bằng cách sử dụng dữ liệu cảm biến thô, các chức năng xử lý hình ảnh và các cài đặt LiDAR tùy chỉnh cho ngành công nghiệp ô tô.
- Cvedia – Tạo ra các hình ảnh tổng hợp để đơn giản hoá việc tìm nguồn cung cấp khối lượng lớn dữ liệu gán nhãn, có thực và trực quan. Nền tảng mô phỏng này sử dụng nhiều cảm biến để tổng hợp môi trường ảnh thực tế nhằm tạo tập dữ liệu thực nghiệm.
- DataGen – Sử dụng cho môi trường nội thất như cửa hàng thông minh, robot trong nhà và thực tế tăng cường.
- Diveplane – Tạo ra các tập dữ liệu tổng hợp sinh đôi cho ngành y tế với cùng thuộc tính thống kê với dữ liệu gốc.
- Gretel – Với mục tiêu trở thành GitHub của dữ liệu, công ty sản xuất các bộ dữ liệu tổng hợp cho các nhà phát triển để giữ lại những insight giống như nguồn dữ liệu ban đầu.
- Hazy – tạo ra các tập dữ liệu để tăng cường phát hiện gian lận tài chính và rửa tiền nhằm chống hành vi phạm tội tài chính.
- Mostly AI – tập trung vào ngành bảo hiểm và tài chính, là một trong những công ty đầu tiên tạo ra dữ liệu tổng hợp có cấu trúc.
- OneView – Phát triển các tập dữ liệu tổng hợp ảo để phân tích hình ảnh quan sát trái đất bằng các thuật toán máy học.
*Theo VentureBeat